High Level Design
Table of Contents
- 1. Introduction
- 1.1. High Level Design (HLD)
- 1.2. Network Protocols
- 1.3. CAP Theorem
- 1.4. Components
- 1.5. Some Important Terms
- 1.6. Scalability
- 1.7. Consistent Hashing
- 1.8. Database Sharding
- 1.9. Caching
- 1.10. Single Point of Failure
- 1.11. NoSQL Databases
- 1.12. Reverse Proxies
- 1.13. Database Replication
- 1.14. Hotspots
- 1.15. Failover Mechanisms
- 1.16. Heartbeats and Health Checks
- 1.17. Circuit Breakers and Retries
- 1.18. Message Queues and Event Streaming
- 1.19. Monolith vs Microservices
- 2. Let's Design!
1. Introduction
1.1. High Level Design (HLD)
It lays out the overall architecture of a system, which describes how components interact with each other, what services exist, and how data flows among them. This is where the website is hosted: https://github.com/hash-define-organization/hld-primer
1.2. Network Protocols
A network protocol defines the rules for the communication between two computers.
1.2.1. Application Layer
- Client Server Protocols
There exists a server and multiple clients that connect to these servers. The clients send requests to the server and the server sends a response.
- HTTP
- Hyper text transfer protocol.
- One connection is created.
- FTP
- File transfer protocol.
- Two connections are created (control connection, data connection).
- Control connection is persistent while data connection may disconnect.
- SMTP
- Simple mail transfer protocol
- Used for sending emails
- IMAP is used for receiving emails
- Web sockets Bi-directional; the server can send requests as well. Mostly used for messaging services.
- HTTP
- Peer-to-Peer (P2P) Protocols
The clients and servers, all of them can talk to each other which makes it fast.
- WebRTC
1.2.2. Transport Layer
These are used to send data over IP networks.
- TCP/IP
- Transmission control protocol
- It provides a reliable, connection oriented delivery (handshakes).
- The order in which data packets are sent is preserved.
- If a data packet is not received, it is requested again.
- Latency is higher.
- Used for file transfer, web (HTTP/HTTPS), email, SSH
- UDP
- User datagram protocol
- It is unreliable because there is no re-transmission of lost data packets.
- Order is not preserved.
- Lower latency
- Used for gaming, VoIP, streaming, broadcast
1.3. CAP Theorem
| Really fun introduction to cap theorem: http://ksat.me/a-plain-english-introduction-to-cap-theorem |
This theorem allows us to choose the right database for our application. It states that any database can have just two of these three properties. No database can exhibit all three of these properties simultaneously. So when choosing a db, you have to compromise on one of these properties.
- C: Consistency This is different from the consistency mention in "ACID". Here, it means that in all the nodes of a distributed system, each node has the same, consistent view of the replicated data. For example, if there are 3 nodes in a distributed database, then all nodes must have the same data. If data is modified in one, it should be reflected in all other nodes.
- A: Availability Every node, must be able to respond in a reasonable amount of time. If a node wants to interact with another node, it should always be able to do so. In other words, every request should get a response (and not an error).
- P: Partition Tolerance Partition tolerance means that the system can continue to operate even if the network has some fault causing problems in communication between two nodes.
In real world distributed systems, you always have to choose between CP and AP.
1.3.1. CA: Consistency and Availability
- Impractical in real distributed systems because you really need partition tolerance, as network partitions are unavoidable.
- Good for single node dbs on a single machine
1.3.2. CP: Consistency and Partition Tolerance
- System prefers correctness over uptime
- The nodes may refuse requests untill consistency is restored.
- Examples: HBase, MongoDB
1.3.3. AP: Availability and Partition Tolerance
- System prefers availability.
- Preferred when you don't always need to show the latest data. For example, you don't really need to see the most accurate Instagram follower count. It will eventually be updated so it's fine.
- The system is always available.
- I really like this one.
- Eg: Cassandra, DynamoDB, CouchDB, DNS
1.4. Components
1.4.1. Load Balancers
- A load balancer distributes requests evenly across different servers.
- So if there are a lot of requests, a load balancer will send different requests to different servers evenly, so that no server is overloaded.
- It may be a networking device or a software application.
- If a server fails, the load balancer routes requests to servers in good condition instead.
- They enable horizontal scaling.
- Types
- Hardware LB - Specialized devices
- Software LB - Just applications that work as load balancers
- Cloud LB - Services you can buy online to balance load (AWS, Google Cloud and Azure provide this)
- there are more… go search..
- Problems
- Single point of failure: If the load balancer itself has some issues then..
- Maybe expensive
- Configuring them is a challenge
1.4.2. Caching
- A technique for temporarily storing frequently requested data for quick access.
- Sending requests to databases can be slower, so caching some data helps speed up things.
- Specialized caching software is used like Redis, which stores this temporary data in RAM which is fast.
1.4.3. Content Delivery Network (CDN)
- A CDN is a specialized network of servers, which hosts media files like images, videos, audios, webpages, or other stuff.
- Whenever a client requests this type of data, the request is handled by a nearby CDN server which has cached copy of this content, instead of the main server.
1.4.4. API Gateways
- An API gateway provides an interface for clients to access different services of a backend system.
- It has routes which the client can send requests to for different purposes and receive a response.
1.4.5. Key-Value Stores
- They store values in key-value pairs just like hashmaps do.
- If it is a persistent store, the data is saved on disk.
1.4.6. Rate Limiters
- They restrict the rate at which a system or application responds to requests.
- These can help prevent DDoS attacks.
1.4.7. Monitoring Systems
- These systems are used to collect and analyze various metrics like performance data.
1.4.8. Messaging Queues
- They allow communication between two components of a system using a queue (FIFO).
- One service sends a message to the queue and then goes back to doing its work.
- The service which needs to act on this message receives it and does the required action.
- Both are independent of each other and don't need to interact directly.
1.4.9. Distributed Unique ID Generator
- They create unique IDs to help identify different components of a distributed system.
1.4.10. Distributed Task Schedulers
- Responsible for scheduling and executing tasks in a distributed system.
1.5. Some Important Terms
1.5.1. Throughput
- Throughput is defined as the amount of information processed in a certain period of time.
- You can think of it like the number of actions performed per unit of time.
- Higher throughput is considered better.
- Unit is bits per second.
1.5.2. Latency
- Amount of time required for a single packet of information to be delivered.
- It is measured in milliseconds.
- Generally, we aim for high throughput and decent latency.
- It mainly depends on -
- Network delays
- Delays due to mathematical calculations
1.5.3. Availability
- The amount of time a system is available which is measured as - \(availability = \frac{uptime}{uptime + downtime}\)
1.6. Scalability
1.6.1. What is scalability?
An application is said to be scalable if it is able to support growth or manage increasing workload without compromising performance. It helps in -
- Ensuring availability
- Maintaining cost effectiveness
- Increasing performance
- Managing growth
- Vertical Scaling
- Just buy a better server, or add more power to your server like adding more RAM, better CPU, more storage, etc..
- At a certain point, you can no longer benefit from vertical scaling.
- Horizontal Scaling
- Buy more servers and form a network.
- The queries will be distributed among all the servers by a load balancer.
- Requests are a little slower but this scales very well, you just have to add more servers.
- Data duplication is required to maintain consistency or you just don't have consistency.
1.7. Consistent Hashing
It is a technique commonly used to balance load across servers in a load balancer. It's mainly used to balance load across distributed databases.
1.7.1. Hashing
- A load balancer could use a hashing function to determine which node to store the data on.
- For instance, if you had three databases, then a simple hash function
k % 3would determine the target db's index. - For example, for user
4, the data would be stored on server4 % 3which is1. - Now if let's say you want to add another database node, you would have to shift ALL the data because the hash function would provide you a different value.
- This is problematic and may be very expensive if there is a LOT of data.
1.7.2. Consistent Hashing
- We imagine that our servers are spread across a clock (1-12).
- There are 3 servers at positions 1, 3 and 9.
- Let's say our hash function returned
8. There's no server at position 8, so moving clockwise, it would reach server 9. - So we can do this for all requests.
- Let's say another node is added on position
7. - Previously, for hash values 4, 5, 6, 7 and 8, all data was stored in server 9.
- But now the values 4, 5, 6, and 7 should correspond to the server at position 7, so we just have to some data present in server 9 to server 7.
- We can leave other DBs unchanged, which saved us cost and time.
1.8. Database Sharding
- Used for horizontal scaling of databases.
- A database with a lot of records is split into smaller databases, for example, one DB with 1 million rows could be split into five DBs with 200K rows each.
- Each chunk is called a "shard" where each shard has the same database schema as the other shards.
1.8.1. Sharding Methods
- Key Based Sharding
- Also known as hash-based sharding.
- Primary keys or some unique identifiers are used as input to a hash function which outputs a hash value.
- This hash value is used to determine which shard to refer to.
- You can use consistent hashing here as well.
- Range Based Sharding
- Also known as horizontal sharding.
- Ranges of values are used to determine the target shard.
- For example, all users with first letters of their names from A-P will be stored in shard 1, P-Z in shard 2.
- Vertical Sharding
- Instead of spliting by rows, we split by columns.
- For example, first shard may only store the name column, second shard stores the email column etc..
1.9. Caching
- Caching is a technique which allows you to answer frequently asked queries faster.
- It works by storing responses to frequent queries in memory, so that the server won't have to ping the database again and again.
- A cache has limited memory, so you have to choose a cache policy to decide what data to evict from the cache when it's full.
- You already know about two simple cache policies: LRU and LFU.
- In distributed systems, servers use a distributed cache like Redis which is its own independent component in the system.
- Whenever data is requested, the cache is queried first. If data is found (cache hit), it is returned (querying a cache is much faster than querying a DB).
- If the requested data does not exist in the cache, it is known as a cache miss.
- A bad caching policy can cause a lot of cache misses, which is known as "thrashing".
1.9.1. Types of Cache
- Application Server Cache
The server itself has a small cache. The advantage is that the response is instant. The drawback is that each server node has its own cache, so consistency is harder to maintain and maintaining consistency will slow things down.
.webp)
- Distributed Cache
- Consistent hashing is used to determine which cache node has the requested data.
- Each server can now independently use the distributed cache system.

- Global Cache
- There's just ONE global cache which is queried whenever data is requested.
- It is the responsibility of the global cache to query the DB in case of a cache miss.

1.10. Single Point of Failure
- A single point of failure occurs when you have a system where there is one component which fails and due to that, the entire system goes down.
- So let's say, you just had one server node and for some reason like a power cut, it crashed. Then, the entire application would stop responding to users.
- Single point of failure applies to server nodes, databases, load balancers, or literally anything that is a component of a system.
1.10.1. Example
- Let's say we have a simple system

- If the server fails, the entire system goes down, this is single point of failure.
- To avoid this, we can add multiple server nodes

- But how do the clients know now which server to connect to?
- For that, we will add a load balancer.
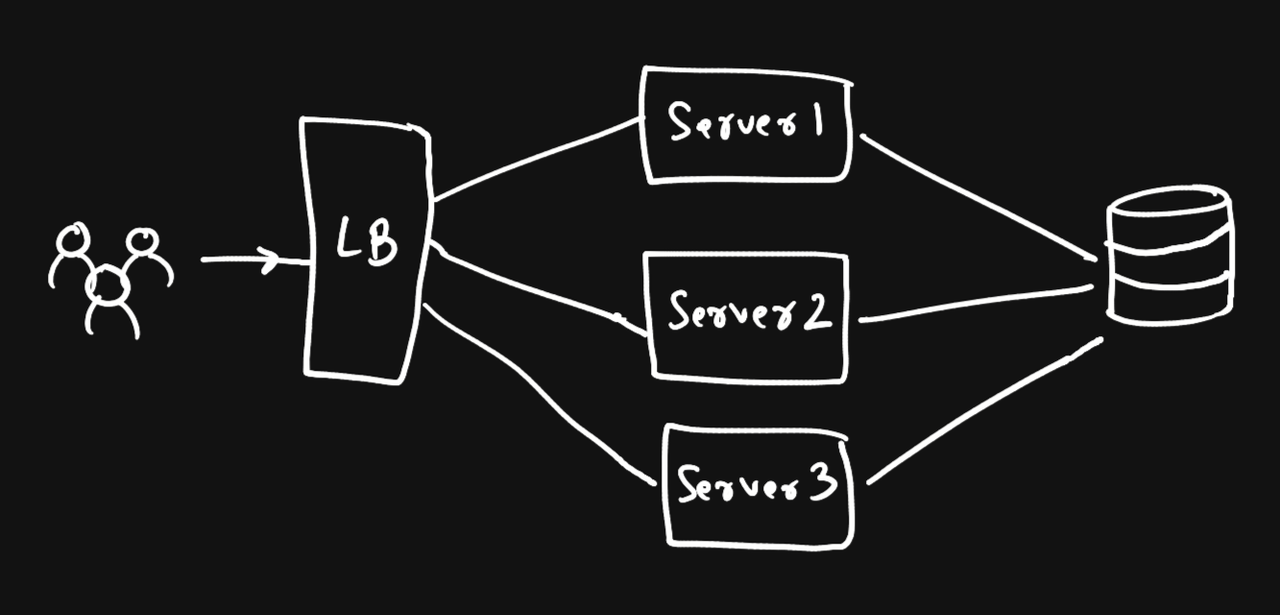
- The server thing is sorted. Yay! But what if the DB goes down? Just add more…
 This is called a master slave configuration. There are other configurations as well (discussed later)
This is called a master slave configuration. There are other configurations as well (discussed later) - Similarly we have to add multiple load balancers as well so that if one goes down, others can work.
 We also had to add a DNS service which allows clients to connect to a load balancer.
We also had to add a DNS service which allows clients to connect to a load balancer. - You may be wondering what if the DNS service goes down? For that we use multiple DNS service providers. Sorted.
- What if the entire application is hosted in Japan and suddenly there's an earthquake? For that, we host our application on different regions.
1.11. NoSQL Databases
- You've studied about SQL databases in DBMS, you know how they require you to model all relationships as tables.
- SQL databases require normalization/de-normalization to remain performant, which is an added task.
- Many NoSQL databases use a JSON like format, for example, MongoDB.
- Many of them are key-value based, graph based etc..
1.11.1. Advantages
- They are horizontally scalable (SQL dbs are vertically scalable).
- They are more available.
- They have a flexible schema, which you can change easily.
1.11.2. Disadvantages
- ACID properties are not guaranteed.
- Less consistency.
- These are not read optimized (SQL DBs are better at reads).
- No information about relations between different entities.
- Joins are hard.
1.11.3. When should I use SQL DBs?
- When you need strong ACID properties. For example, banking systems (transactions), inventory management, payments etc..
- When your data has a fixed, well-defined schema.
- When you require complex queries for analytics (SQL is a powerful language!).
- When data integrity matters.
- When you expect moderate-high read/write consistency.
1.11.4. When should I use NoSQL DBs?
- When you have flexible, evolving schemas or unstructured data. For example, storing analytics, json documents, etc.
- When you need horizontal scaling and partitioning (a lot of horizontally distributed SQL DBs do exist though).
- When you need simple queryies.
- When you need low latency at massive scale.
1.12. Reverse Proxies
- It is a middleman which sits between clients and servers.
- Its primary purpose is to shield backend servers from the clients. The clients won't know which server their request will go to.
- They also perform SSL Termination. You know that in "https", "s" stands for secure. It means that "https" calls are encrypted. Reverse proxies decrypt these calls before sending them to the servers.
- They can also perform load balancing. So a load balancer, is just a specific type of reverse proxy.

1.13. Database Replication
- It is a technique which involves copying data from one database to one or more databases to
- Improve availability (prevent single point of failures)
- Read scalability (clients can send read requests to these DBs)
- Save a backup
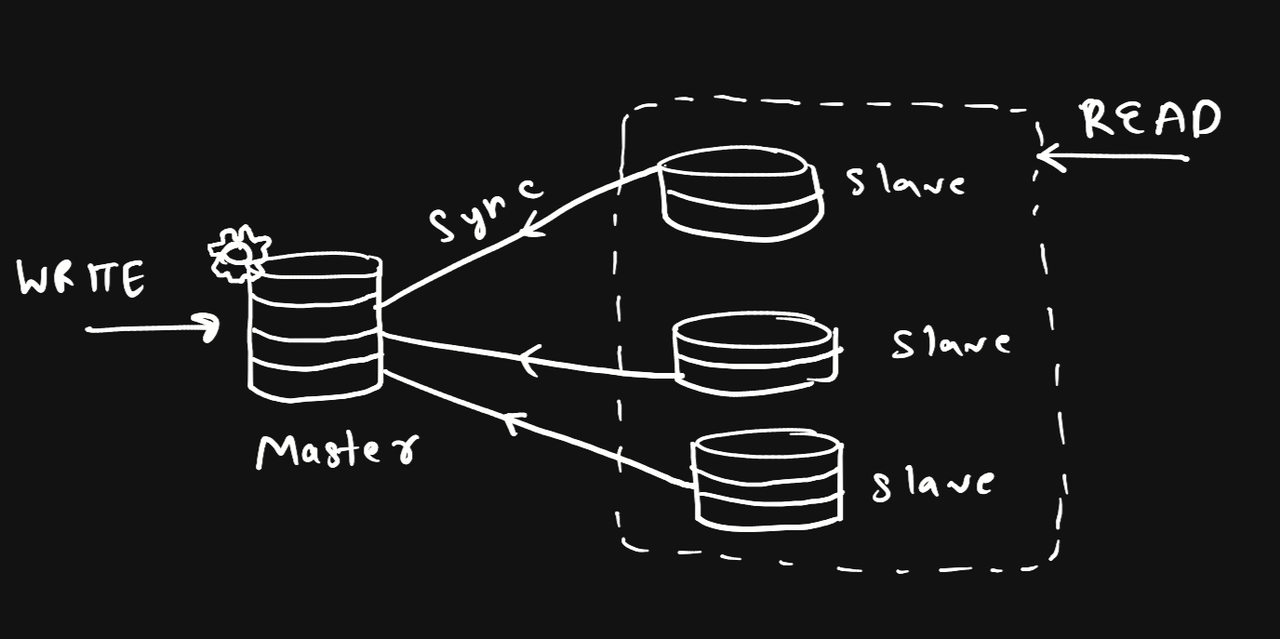
1.13.1. Master-Slave Configuration
- There is a master DB which handles all write requests.
- There are multiple slave DBs which handle all read requests.
- When data is written to master, it is asynchronously or synchronously copied to the slaves.
- Advantage is that it provides easy READ scaling.
- Disadvantage is that the master becomes a single point of failure :(
1.13.2. Master-Master Configuration
- Multiple nodes can accept writes.
- Changes are replicated to all other nodes to maintain consistency.
- There is no single point of failure -> high availability.
- Conflicts may arise as two nodes may write different values to the same record simultaneously.
- Timestamps may be used to fix this issue. The latest timestamp wins.
1.14. Hotspots
- A hotspot occurs when a single node receives a disproportionate amount of traffic when compared to other nodes. It may happen to any kind of component like servers, database nodes, load balancers, etc..
- For example
- Product A is trending and is requested a lot more times than other products in the cache, so the cache becomes a hotspot here.
- One server handles most of the requests due to poor load balancing.
- Using poor hashing functions causing traffic in one DB node to spike.
- To fix hotspots
- You may shard/partition even further.
- Use better load balancing algorithms.
- Rate limiting requests per client can help.
- Precompute duplicate data to reduce heavy queries hitting a single table/row.
 A cashier with a long queue can be considered a hotspot. To solve this, you may introduce more cashier counters and ask people to move to those instead.
A cashier with a long queue can be considered a hotspot. To solve this, you may introduce more cashier counters and ask people to move to those instead.
1.15. Failover Mechanisms
- Whenever there is a point of failure, failover mechanisms are used to switch to backup components.
1.15.1. Active-Passive
- There is an active component and a passive component.
- When the active component goes down, the passive one takes over.
- Simpler but passive component is idle most of the time.
1.15.2. Active-Active
- Multiple nodes are active at once.
- If one fails, others continue running without disruption.
- For example, multiple servers behind a load balancer.
- More efficient use of resources, but harder to maintain consistency.
1.16. Heartbeats and Health Checks
1.16.1. Heartbeats
- A heartbeat is a signal which indicates if a server node is alive or not.
- Each server keeps on sending a signal like "I'm alive".
- If there is no heartbeat, the node is considered down. So load balancers remove them from rotation.
1.16.2. Health Checks
- A node periodically pings different servers.
- For example, there may be a
/healthendpoint which may send response200 OKif the server is fine. - In both cases, failure mechanisms are used to take action.
1.17. Circuit Breakers and Retries
1.17.1. Circuit Breakers
- They protect your system from cascading failures (cascading mean something like a domino effect where one crash causes the next node to crash then the next and so on).
- For example, If a payment service is down, your API will stop sending requests to that service until it is healthy again.
1.17.2. Retries
- When receiving a failed response, clients may retry a few more times.
- Exponential backoff may be used. For example, try at 1sec, then 2sec, then 4sec, then 16sec, then 32sec and so on to avoid flooding a struggling service.
- It is combined with circuit breakers to prevent infinite retries.
1.18. Message Queues and Event Streaming
1.18.1. Message Queue/Broker
- A message queue is a middleware that lets different services communicate asynchronously by passing messages.
- So service A does not call service B directly. It passes its message to the message queue. Whenever service B is available, it picks it up.
- Service A and B can keep doing their work independently without blocking other clients.
- Some examples are Kafka, RabbitMQ, AWS SQS, etc..

1.18.2. Publisher-Subscriber Pattern (Pub/Sub Pattern)
- One publisher broadcasts a message which multiple subscribers can consume.
- For example, Service A broadcasts "Order created". Service B (billing) and Service C (inventory), which subscribed to it, will now act on it.
- Multiple consumers can react differently on the same event at the same time.
1.19. Monolith vs Microservices
1.19.1. Monolith
- This is a server architecture where there is just a single, unified codebase.
- All services resides in just one codebase.
- There is only one thing to deploy here.
- It is simple to build but very hard to scale.
- You would have to scale the entire server instead of an individual service.
- Tight coupling.
1.19.2. Microservices
- System is decomposed into multiple small services.
- Each service can be scaled individually depending on the requirements.
- One service goes down, the rest are unbothered.
- Services are loosely coupled.
- For inter-service communication, gSRP is preferred over REST APIs.
2. Let's Design!
- We'll gradually increase the difficulty here. Let's start with easy problems first.
2.1. Warm-Up
2.1.1. URL Shortener Design
Recommended video: https://www.youtube.com/watch?v=qSJAvd5Mgio